
深入理解String的intern()方法
一、String基本特征
Java中的字符串String,使用
""引起来表示。两种实例化方式:String s1 = “hello”;String s2 = new String("hello");
String声明为final的,不可被继承
String类实现了Serializable接口、Comparable接口。
String类重写了
equals()方法,代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13//JDK 15
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String aString = (String)anObject;
if (!COMPACT_STRINGS || this.coder == aString.coder) {
return StringLatin1.equals(value, aString.value);
}
}
return false;
}JDK8之前,String使用char型数组存放数据,JDK9改为byte型数组。修改原因,官方描述如下,参考:
We propose to change the internal representation of the String class from a UTF-16 char array to a byte array plus an encoding-flag field. The new String class will store characters encoded either as ISO-8859-1/Latin-1 (one byte per character), or as UTF-16 (two bytes per character), based upon the contents of the string. The encoding flag will indicate which encoding is used.
String-related classes such as AbstractStringBuilder, StringBuilder, and StringBuffer will be updated to use the same representation, as will the HotSpot VM’s intrinsic string operations.
This is purely an implementation change, with no changes to existing public interfaces. There are no plans to add any new public APIs or other interfaces.
The prototyping work done to date confirms the expected reduction in memory footprint, substantial reductions of GC activity, and minor performance regressions in some corner cases.
String代表不可变的字符序列,详细使用可以参考Java学习笔记09(1)-常用类之String。
通过字面量定义的字符串存储在字符串常量池(String Pool)(JDK7将字符串常量池移到了堆中)中,目的是共享;通过
new创建对象的方式构建的字符串存储在堆(堆中字符串常量池以外的空间)中。字符串常量池中是不会存储相同内容的字符串:
- String Pool 是一个固定大小的
Hashtable(底层采用数组和链表实现,Hashtable无法扩容,这一点不同于HashMap)。如果放进String Pool的String非常多, 就会造成严重的哈希冲突,从而导致链表会很长,而链表长了后直接会造成的影响就是当调用String.intern()时性能会大幅下降。 - 使用
- XX:StringTableSize可设置StringTable的长度 - 在JDK 6中
StringTable的值默认大小为1009,所以如果常量池中的字符串过多就会导致效率下降很快。对于StringTableSize的设置没有要求。 - 在JDK 7中,
StringTable的长度默认值是60013。StringTableSize的设置没有要求。 - 从JDK 8开始,
StringTable长度可设置的最小值要求为1009。
- String Pool 是一个固定大小的
二、String的内存分配
Java中,8中基本数据类型的常量池都是系统协调的,String类型的常量池比较特殊,它的主要使用方法有两种:
- 直接使用
""号,即字面量的方式,声明出来的字符串对象会直接存储在常量池中。- 比如:
String s = "hello";
- 比如:
- 如果不是使用
""的方式(使用new方式,或者和变量拼接等方式)声明的String对象是放在堆中的。可以使用String类提供的intern()方法,intern()方法会从字符串常量池中查询当前字符串是否存在,如果存在,直接返回字符串,若不存在就会将当前字符串放入常量池中并返回。
JDK 6及以前,字符串常量池存放在永久代。
JDK 7中,字符串常量池被移到了堆中(原因:permSize默认空间比较小;永久代垃圾回收频率低):
- 所有的字符串都保存在Heap中,和其他普通对象一样,调优时仅需调整堆大小即可。
- 这次改动让我们重新考虑在JDK 7中使用
String.intern();。因为调整以后,常量池中不需要必须存储一份对象了,可以直接存储堆中的引用。也就是说,调用此方法时,如果堆中已经存在相等的String对象,会直接保存对象的引用,而不会重新创建对象。这一点的体现可以参考下文的例题。
JDK 8中,字符串常量池依然是在堆中。
三、String的基本操作
情况一:Java语言规范(链接)里要求,完全相同的字符串字面量,应该包含同样的unicode字符序列,并且必须是指向同一个String类实例。
1
2
3
4
5
6
7
8
9
10
11
12public class StringTest4 {
public static void main(String[] args) {
System.out.println();//3142个已加载字符串常量
System.out.println("1");//3143
System.out.println("2");//3144
System.out.println("3");;//3145
//如下的字符串"1" 到 "3"不会再次加载
System.out.println("1");//3145
System.out.println("2");//3145
System.out.println("3");//3145
}
}情况二:
1
2
3
4
5
6
7
8
9
10
11
12
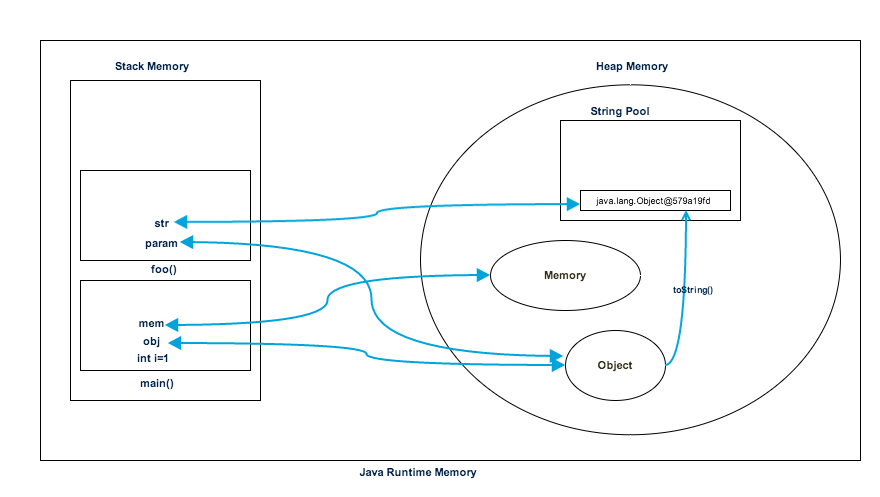
13class Memory {
public static void main(String[] args) {//line 1
int i = 1;//line 2
Object obj = new Object();//line 3
Memory mem = new Memory();//line 4
mem.foo(obj);//line 5
}//line 9
private void foo(Object param) {//line 6
String str = param.toString();//line 7
System.out.println(str);
}//line 8
}上述程序的内存结构如下:

四、字符串拼接操作
1、字符串拼接的特征
字符串拼接有以下特征:
常量与常量的拼接,结果在常量池,原理是编译期优化,生成字节码文件的时候,已经生成了常量的拼接结果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21public class StringTest {
@Test
public void test1(){
String s1 = "a" + "b" + "c";//编译期优化:等同于"abc"
String s2 = "abc"; //"abc"一定是放在字符串常量池中,将此地址赋给s2
System.out.println(s1 == s2); //true
System.out.println(s1.equals(s2)); //true
}
}
/*
在前端编译生成的字节码文件中,已经将s1优化为“abc”
如下为部分字节码文件内容:
0 ldc #7 <abc> 可见,s1的值已经优化为"abc"
2 astore_1
3 ldc #7 <abc>
5 astore_2
6 getstatic #9 <java/lang/System.out>
9 aload_1
10 aload_2
...
*/
常量池中不会存在相同内容的常量。
如果拼接的字符串里有变量,结果在堆中(堆中字符串常量池以外的堆空间),相当于
new了新对象。拼接的原理是StringBuilder。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public class StringTest{
public void test3(){
String s1 = "a";
String s2 = "b";
String s3 = "ab";
String s4 = s1 + s2;
System.out.println(s3 == s4);//false
}
}
/*
上述的s1 + s2 的具体执行细节:(变量s是为了容易理解定义的,实际上是匿名的)
① StringBuilder s = new StringBuilder();
② s.append("a");
③ s.append("b");
④ s.toString(); --> 约等于 new String("ab")
补充:在jdk5.0之后使用的是StringBuilder,在jdk5.0之前使用的是StringBuffer
s3在堆中的字符串常量池中,而s4在堆中字符串常量池以外的位置,因此二者地址不相等
*/上述程序的字节码文件如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
240 ldc #47 <a>
2 astore_1
3 ldc #49 <b>
5 astore_2
6 ldc #51 <ab>
8 astore_3
9 new #33 <java/lang/StringBuilder>
12 dup
13 invokespecial #35 <java/lang/StringBuilder.<init>>
16 aload_1
17 invokevirtual #36 <java/lang/StringBuilder.append>
20 aload_2
21 invokevirtual #36 <java/lang/StringBuilder.append>
24 invokevirtual #40 <java/lang/StringBuilder.toString>
27 astore 4
29 getstatic #9 <java/lang/System.out>
32 aload_3
33 aload 4
35 if_acmpne 42 (+7)
38 iconst_1
39 goto 43 (+4)
42 iconst_0
43 invokevirtual #15 <java/io/PrintStream.println>
46 return通过变量拼接字符串的过程,可以总结如下,当遇到有变量的字符串拼接时:
- 首先使用
new方式创建StringBuilder对象(JDK 5.0之前是StringBuffer) - 然后调用
append()方法,将要拼接的字符串内容添加到StringBuilder对象中 - 最后调用
StringBuilder对象的toString()方法,将其转换为String类型,赋给指定的变量。
- 首先使用
此外,还需要注意的是,如果字符串拼接是变量,但是是用final修饰的,此时这种变量就是常量,同样在编译期优化,结果存放到字符串常量池中:
1 | |
建议:针对于final修饰类、方法、基本数据类型、引用数据类型的量的结构时,能用final时尽量使用。这样前端编译期就能赋值,提高运行效率。
- 如果拼接的结果调用
intern()方法,则主动将常量池中没有的字符串对象放入池中,并返回此对象的地址(引用,reference),具体参加下一节内容。
2、‘+’号和append方法对比
对于字符串拼接,可以使用+号直接拼接字符串,也可以在StringBuffer/StringBuilder对象中使用append()方法,二者的效率对比如下:
1 | |
以上结果表明,使用StringBuffer/StringBuilder对象中的append()方法进行字符串拼接,效率要远高于+号拼接String的方式。
- 使用
+号拼接时,每次都需要创建一个StringBuffer/StringBuilder对象,然后调用append()方法添加内容,最后调用toString()方法生成String对象并重新赋值。 - 使用
append()方式,只创建了一个StringBuffer/StringBuilder对象,因此效率要高很多。 - 此外,用String的字符串拼接方式,内存中由于创建了较多的
StringBuilder和String的对象,内存占用更大,如果进行GC,需要花费额外的时间。
因此,实际开发中,如果需要大量的字符串操作,尽量使用StringBulider。
如果确定字符串长度不高于某个值的情况下,建议使用带参的构造器实例化StringBuilder,底层会一次性申请指定长度的数组,这样可以避免频繁扩容带来的效率降低。
五、intern()的使用
1、intern()方法
JDK源码中intern()方法的定义和描述:
1 | |
根据描述可知,当str调用str.intern()时,如果字符串常量池中已经有和str相等的字符串(使用equals()方法判断),则返回当前字符串(或者说字符串对象的引用);如果没有str字符串的话,会在常量池中生成,然后再返回此字符串。
s.intern() == t.intern()等价于s.equals(t) 为 true
如果不是用""声明的String对象,可以使用String提供的intern()方法,intern()方法会从字符串常量池中查询当前字符串是否存在,若不存在就会将当前字符串放入常量池中,比如:
1 | |
也就是说,如果在任意字符串上调用intern()方法,那么其返回结果所指向的那个类实例,必须和直接以常量形式出现的字符串实例完全相同。因此,下列表达式的值必定是true:
1 | |
通俗点讲,Interned String确保字符串在字符串常量池里只有一份拷贝,这样可以节约内存空间,加快字符串操作任务的执行速度。
进一步来说,例如,想要保证变量s指向的是字符串常量池中的数据,比如”hello”这个字符串,有两种方式:
- 直接使用字面量定义的方式,
String s = "hello"; - 调用String类的
intern()方法,比如String s = new String("hello").intern();
无论字符串是怎样方式定义或生成的,只要调用
intern()方法,返回的一定是此字符串在字符串常量池中的引用
2、关于new String()
问题引申一:如果使用new String("ab")方式创建字符串对象,会创建几个对象呢?答案是两个
通过字节码可以看出:
1 | |
字符串常量池中创建了”ab”字符串对象。
问题引申二:如果使用new String("a")+new String("b")方式创建字符串对象,会创建几个对象呢?答案是6个
1 | |
通过字节码文件可知,一共创建了6个对象,分别为:
new StringBuilder(),字节码第0行new String("a"),字节码第7行- 常量池的”a”,字节码第11行
new String("b"),字节码第19行- 常量池的“b“,字节码第23行
toString()方法创建的String对象,字节码第31行
这里的StringBuilder的toString()方法创建了一个String对象:
1 | |
值得注意的是,这里toString()方法只创建了一个String对象,没有在字符串常量池中创建”ab”字符串对象,因为其直接使用数组创建字符串,而不是使用字面量的方式,所以字符串常量池中没有”ab”这个字符串。
3、通过实例进一步理解
例一,参考深入解析String#intern:
1 | |
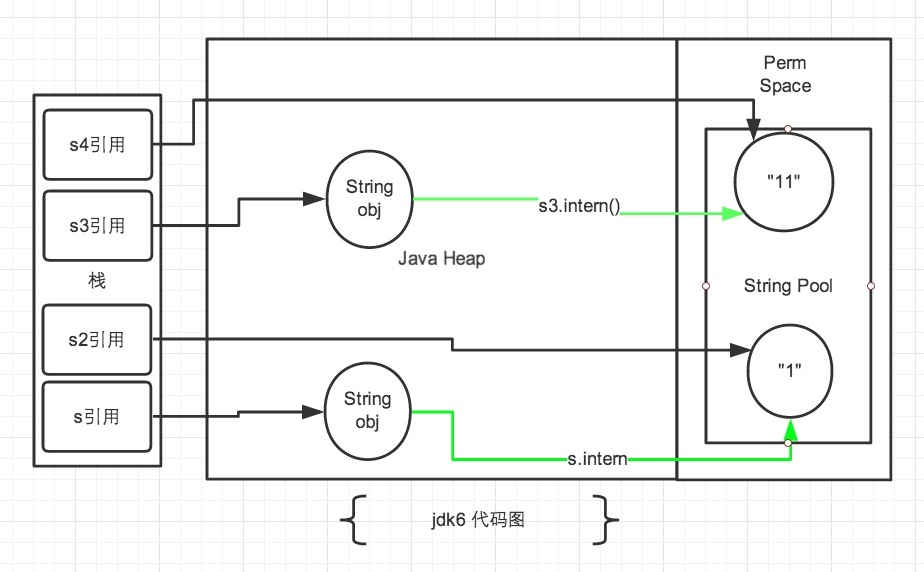
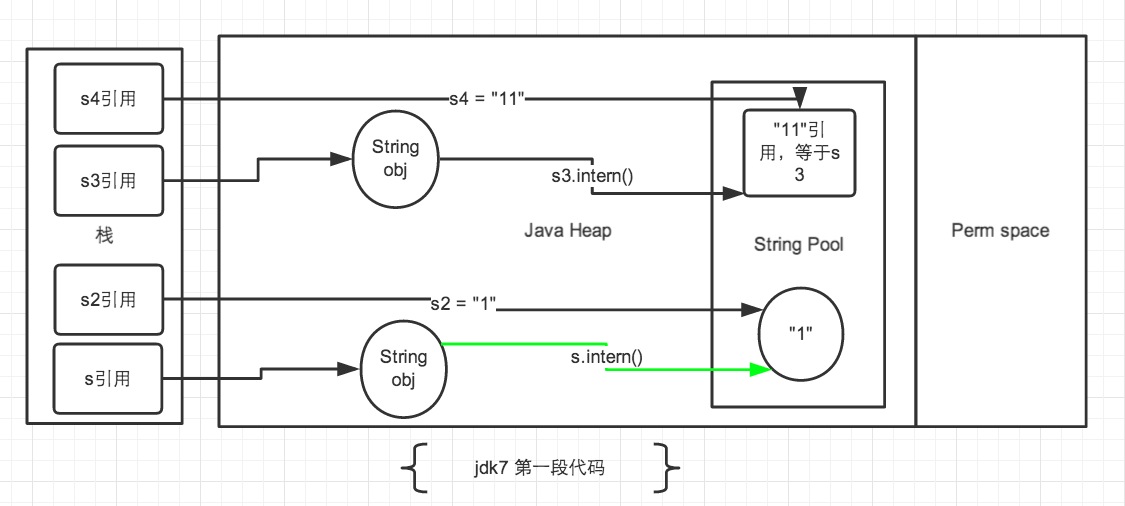
可以看到,在JDK6中结果都是false,而在JDK7及以后的版本中结果为false和true。这是为什么呢?
在JDK6及以前的版本中,常量池放在永久区(Perm区),永久区和Heap区是完全分开的。前面说过,使用
""号声明的字符串直接在字符串常量池中生成,而new出来的String对象放在堆中。因此s和s3都是指向堆中对象的一个引用地址,s2和s4是方法区字符串常量池中对象地址,无论如何都不相等。对于JDK7及以后的版本:
- 先看 s 和 s2 对象。
String s = new String("1");第一句代码,生成了2个对象,即常量池中的“1” 和堆中的String对象。其中s是指向堆中的String对象的引用。s.intern();这一句是 s 对象去字符串常量池中寻找后发现 “1” 已经在常量池里了。因此String s2 = "1";这句代码生成一个 s2的引用指向字符串常量池中的“1”对象。 结果就是 s 和 s2 的引用地址明显不同。 - 对于 s3和s4。
String s3 = new String("1") + new String("1");这句代码生成了字符串常量池中的“1” ,此时s3引用对象内容是”11”,存放在堆中。但此时常量池中是没有 “11”对象的。接下来s3.intern();将 s3中的“11”字符串放入 String 常量池中,因为此时常量池中不存在“11”字符串,常规做法是跟 jdk6 那样,在常量池中生成一个 “11” 的对象,关键点是jdk7 常量池中可以直接存储堆中的引用。因此常量池中存放的是引用,这份引用指向 s3 引用的对象。 也就是说引用地址是相同的。最后String s4 = "11";这句代码中”11”是显式声明的,因此会直接去常量池中创建,创建的时候发现已经有这个对象了,此时也就是指向 s3 引用对象的一个引用,所以 s4 引用就指向和 s3 一样了,最后比较s3 == s4是 true。
- 先看 s 和 s2 对象。
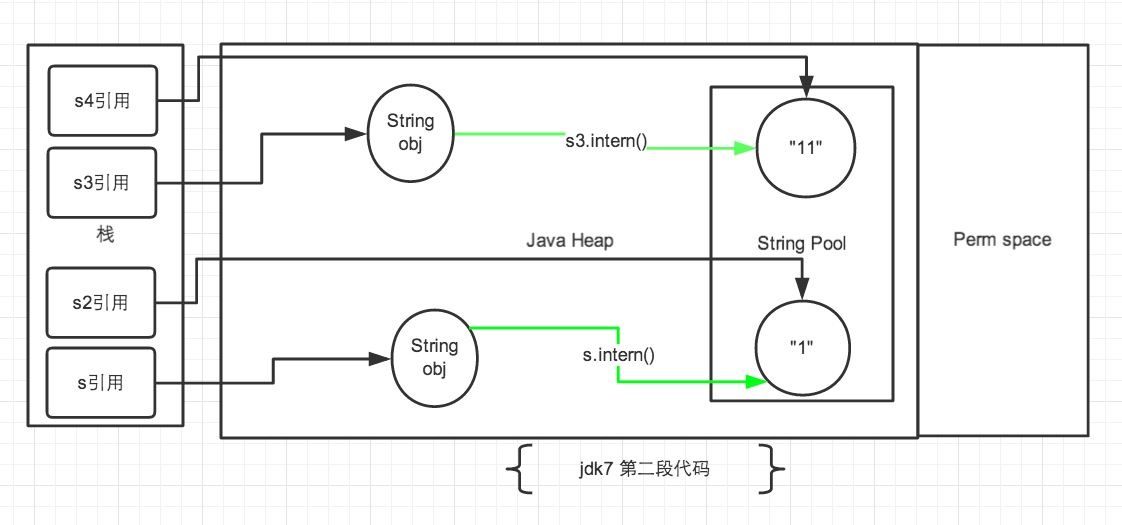
例二,将例一中的intern()语句下调一行:
1 | |
此时不同版本的结果都是false:
- 对于s 和 s2 ,
s.intern();,这一句往后放不会有什么影响,因为对象池中在执行第一句代码String s = new String("1");的时候已经生成“1”对象了。下边的s2声明都是直接从常量池中取地址引用的。 s 和 s2 的引用地址是不会相等的。 - 对于s3和s4,首先执行
String s4 = "11";声明 s4 的时候常量池中是不存在“11”对象的,执行完毕后,“11“对象是 s4 声明产生的新对象,方法返回字符串常量池中“11”的引用赋给s4。然后再执行s3.intern();时,常量池中“11”对象已经存在了,因此 s3 和 s4 的引用是不同的。s3是指向堆中对象的引用,而s4是字符串常量池中的引用,所以结果是false
4、总结
String中intern()的作用:
- 在JDK 6中,
intern()尝试将字符串对象放入字符串常量池。- 如果常量池中有,则不会放入,返回已有的对象地址
- 如果没有,会把此对象复制一份,放入常量池,并返回常量池中对象地址。
- 在JDK7及以后,
intern()尝试将字符串对象放入字符串常量池。- 如果常量池中有,则不会放入,返回已有的对象地址
- 如果没有,会把此对象的引用地址复制一份,放入常量池,并返回常量池中对象引用地址。
5、练习
练习1:
1 | |
练习2:
1 | |
练习3:
1 | |
6、intern()的使用
实际开发中,如果程序中存在大量重复字符串,使用intern()会节省大量空间,与JDK版本无关。
1 | |
通过运行程序可知,使用intern()方法时,占用的空间大小相较于不使用intern()时要小很多,主要原因是因为:
不使用
intern()创建字符串对象,会在堆中生成大量的String对象,且不能回收,导致空间占用很大。使用
intern()方法创建对象,如果字符串常量池中已经存在要创建的对象,则数组元素直接指向字符串常量池中的字符串对象,无需在堆中维护过多的String对象(或者说创建之后可以被回收销毁),因此空间占用小。注意,两种方式在字符串常量池中创建的字符串个数是相等的,区别只是堆中字符串对象的数量不同
实际应用:在大的网站平台,需要内存中存储大量字符串,这时候如果字符串都调用intern()方法,会明显降低内存大小。
关于intern()方法错误的使用,也可以参考深入解析String#intern
六、G1中的String去重操作
Garbage First收集器对String的去重操作,参考官方说明JEP 192: String Deduplication in G1
背景:
对许多Java应用(有大的也有小的)做的测试得出以下结果:
- 堆存活数据集合里面string对象占了25%
- 堆存活数据集合里面重复的string对象有13.5%
- string对象的平均长度是45
许多大规模的Java应用的瓶颈在于内存,测试表明,在这些类型的应用里面,Java堆中存活的数据集合差不多25%是string对象。更进一步,这里面差不多一半string对象是重复的,即string1.equals(string2 )=true。堆上存在重复的string对象必然是一种内存的浪费。在G1垃圾收集器中实现自动持续对重复的strfing对象进行去重,这样就能避免浪费内存。
实现:
- 当垃圾收集器工作的时候,会访问堆上存活的对象。对每一个访问的对象都会检查是否是候选的要去重的string对象。
- 如果是,把这个对象的一个引用插入到队列中等待后续的处理。一个去重的线程在后台运行,处理这个队列。处理队列的一个元素意味着从队列删除这个元素,然后尝试去引用和它一样的string对象。
- 使用一个hashtable来记录所有的被string对象使用的不重复的char数组。当去重的时候,会查这个hashtable,来看堆上是否已经存在一个一模一样的char数组。
- 如果存在,string对象会被调整为引用那个数组,释放对原来的数组的引用,最终会被垃圾收集器回收掉。
- 如果查找失败,char数组会被插入到hashtable,这样以后的时候就可以共享这个数组。
命令行选项:
UseStringDeduplication(bool) :开启String 去重,默认是不开启的PrintStringDeduplicationStatistics(bool) :打印详细的去重统计信息StringDeduplicationAgeThreshold(uintx) :达到这个年龄的String对象被认为是去重的候选对象。
- 本文作者:Kangshitao
- 本文链接:http://kangshitao.github.io/2021/05/10/understanding-string-intern/index.html
- 版权声明:本博客所有文章均采用 BY-NC-SA 许可协议,转载请注明出处!
