m3u8文件+ts文件是很多流媒体网站常用的一种方法,本文作为爬虫练习项目,记录了如何使用python爬虫爬取某视频网站的视频资源。
一、分析
第一步是确定想要爬取的资源地址,通过网页源代码找到资源的url。
F12进入开发者模式,找到m3u8后缀的文件,可以看到有两个,把第一个m3u8文件下载下来以后发现,其内容是第二个m3u8的地址,第二个m3u8的url才是真实的地址

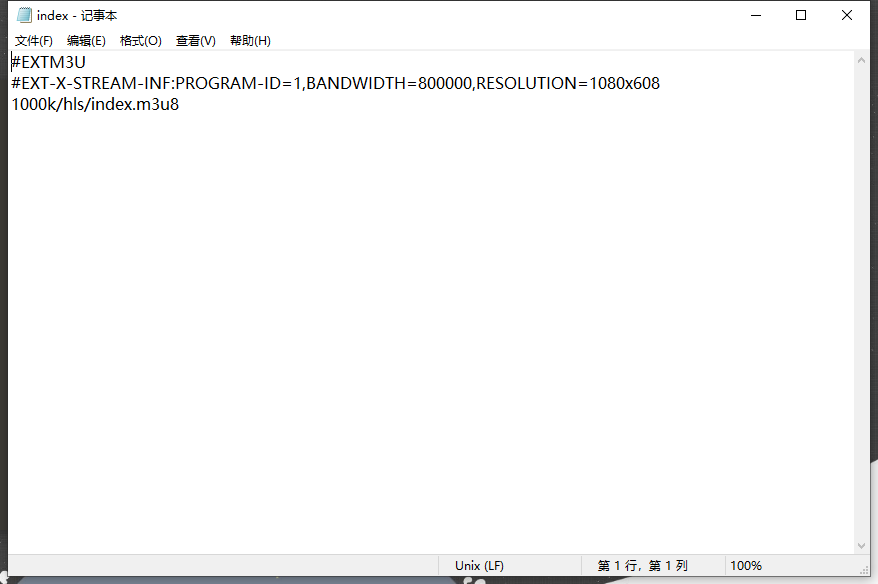
第一个m3u8文件内容
可见,第一个m3u8文件的内容,是真正的m3u8的地址。
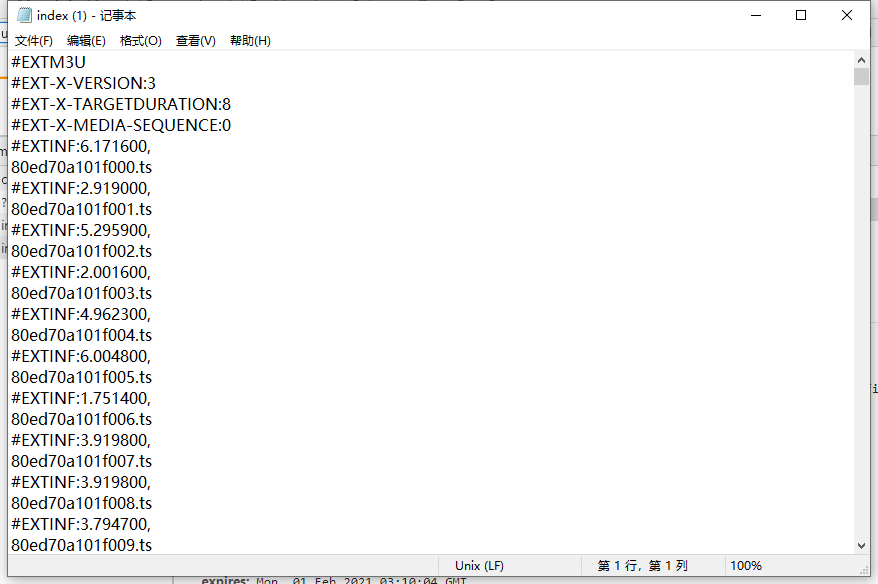
第二个m3u8文件内容
第二个m3u8文件中的内容才是真正的ts文件的地址。
每一集视频是由多个ts文件构成的,将这些ts文件拼接起来就是完整的一集内容。这些ts文件的url都保存到第二个m3u8文件中。因此可以确定大体流程:
- 获取当前集的m3u8地址,并下载m3u8文件。
- 从m3u8文件中获取ts视频的url。
- 根据ts文件的url下载视频。
- 将多个ts文件合并,得到完整的一集内容,保存到相应路径。
二、获取m3u8文件
分析网页源代码,可以看到m3u8的url保存在一个playurls的列表中,并且一季的所有集的地址都在,因此只需要在其中一集的网页源代码中获取出当前季的所有集的url即可:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
def get_m3u8_list(url,S):
req = requests.get(url)
req.encoding = 'utf-8'
html = req.text
res_url = re.findall(r'https:\\/\\/youku.com-youku.net.*?index.m3u8', html, re.S)
m3u8list = []
for i in range(len(res_url)):
url = res_url[i].split('\\')
m3u8list.append(''.join(url[:-1])+'/1000k/hls/index.m3u8')
print(m3u8list[i])
print('第{}季m3u8地址获取完毕'.format(S))
return m3u8list
|
常规思路是获取到第一层m3u8文件,然后从中获取到真正的m3u8的地址,通过分析,真正的url是在第一层的url后面两个文件路径(仅对于当前视频网站,具体需要根据实际情况分析),这里手动添加上了,没有读取文件。
三、获取ts文件url并下载
获取到m3u8文件的地址后,就可以下载文件,通过读取文件内容,获取到当前集的所有ts文件url,然后下载。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
def download(m3u8_list,base_path,S):
print('下载m3u8文件...')
url = base_path+'Shameless_'+'S'+str(S)
path = Path(url)
if not path.is_dir():
os.mkdir(url)
for i in range(len(m3u8_list)):
print('正在下载第{}集...'.format(i+1))
start = datetime.datetime.now().replace(microsecond=0)
time.sleep(1)
ts_urls = []
m3u8 = requests.get(url=m3u8_list[i])
content = m3u8.text.split('\n')
for s in content:
if s.endswith('.ts'):
ts_url = m3u8_list[i][:-10] + s.strip('\n')
ts_urls.append(ts_url)
download_ts(ts_urls,down_path=url+'//'+"E"+str(i+1)+'.ts')
end = datetime.datetime.now().replace(microsecond=0)
print('耗时:%s' % (end - start))
print('第{}集下载完成...'.format(i+1))
def download_ts(ts_urls,down_path):
file = open(down_path, 'wb')
for i in tqdm(range(len(ts_urls))):
ts_url = ts_urls[i]
time.sleep(1)
try:
response = requests.get(url=ts_url, stream=True, verify=False)
file.write(response.content)
except Exception as e:
print('异常请求:%s' % e.args)
file.close()
|
四、总结
完整代码
完整代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
| import requests
import re
import os
from pathlib import Path
import time
import datetime
from tqdm import tqdm
import urllib3
urllib3.disable_warnings()
def get_m3u8_list(url,S):
req = requests.get(url)
req.encoding = 'utf-8'
html = req.text
res_url = re.findall(r'https:\\/\\/youku.com-youku.net.*?index.m3u8', html, re.S)
m3u8list = []
for i in range(len(res_url)):
url = res_url[i].split('\\')
m3u8list.append(''.join(url[:-1])+'/1000k/hls/index.m3u8')
print(m3u8list[i])
print('第{}季m3u8地址获取完毕'.format(S))
return m3u8list
def download(m3u8_list,base_path,S):
print('下载m3u8文件...')
url = base_path+'Shameless_'+'S'+str(S)
path = Path(url)
if not path.is_dir():
os.mkdir(url)
for i in range(len(m3u8_list)):
print('正在下载第{}集...'.format(i+1))
start = datetime.datetime.now().replace(microsecond=0)
time.sleep(1)
ts_urls = []
m3u8 = requests.get(url=m3u8_list[i])
content = m3u8.text.split('\n')
for s in content:
if s.endswith('.ts'):
ts_url = m3u8_list[i][:-10] + s.strip('\n')
ts_urls.append(ts_url)
download_ts(ts_urls,down_path=url+'//'+"E"+str(i+1)+'.ts')
end = datetime.datetime.now().replace(microsecond=0)
print('耗时:%s' % (end - start))
print('第{}集下载完成...'.format(i+1))
def download_ts(ts_urls,down_path):
file = open(down_path, 'wb')
for i in tqdm(range(len(ts_urls))):
ts_url = ts_urls[i]
time.sleep(1)
try:
response = requests.get(url=ts_url, stream=True, verify=False)
file.write(response.content)
except Exception as e:
print('异常请求:%s' % e.args)
file.close()
if __name__ == '__main__':
savefile_path = 'F://Shameless//'
section_url = ['http://www.tv3w.com/dushiqinggan/wuchizhitudiyiji/5-1.html',
'http://www.tv3w.com/dushiqinggan/wuchizhitudierji/3-1.html',
'http://www.tv3w.com/dushiqinggan/wuchizhitudisanji/4-1.html',
'http://www.tv3w.com/dushiqinggan/wuchizhitudisiji/4-1.html',
'http://www.tv3w.com/dushiqinggan/wuchizhitudiwuji/7-1.html',
'http://www.tv3w.com/dushiqinggan/wuchizhitudiliuji/7-1.html',
'http://www.tv3w.com/dushiqinggan/wuchizhitudiqiji/6-1.html']
for i in range(len(section_url)):
print('开始下载第{}季...'.format(i+1))
episode_url = get_m3u8_list(url=section_url[i],S=i+1)
download(episode_url,savefile_path,i+1)
print('done')
|
目标网站的资源前七季的源是同一个,这里只获取前七季。
改进
第一次写完整的爬虫代码,可以改进的地方有很多:
- 可以改为自动获取m3u8真实地址。
- 使用多线程下载,提高下载速度。
- 添加文件验证机制,确保下载正确。
参考链接
- Python爬虫——从流媒体网站获取的m3u8爬取视频
- 爬取m3u8视频

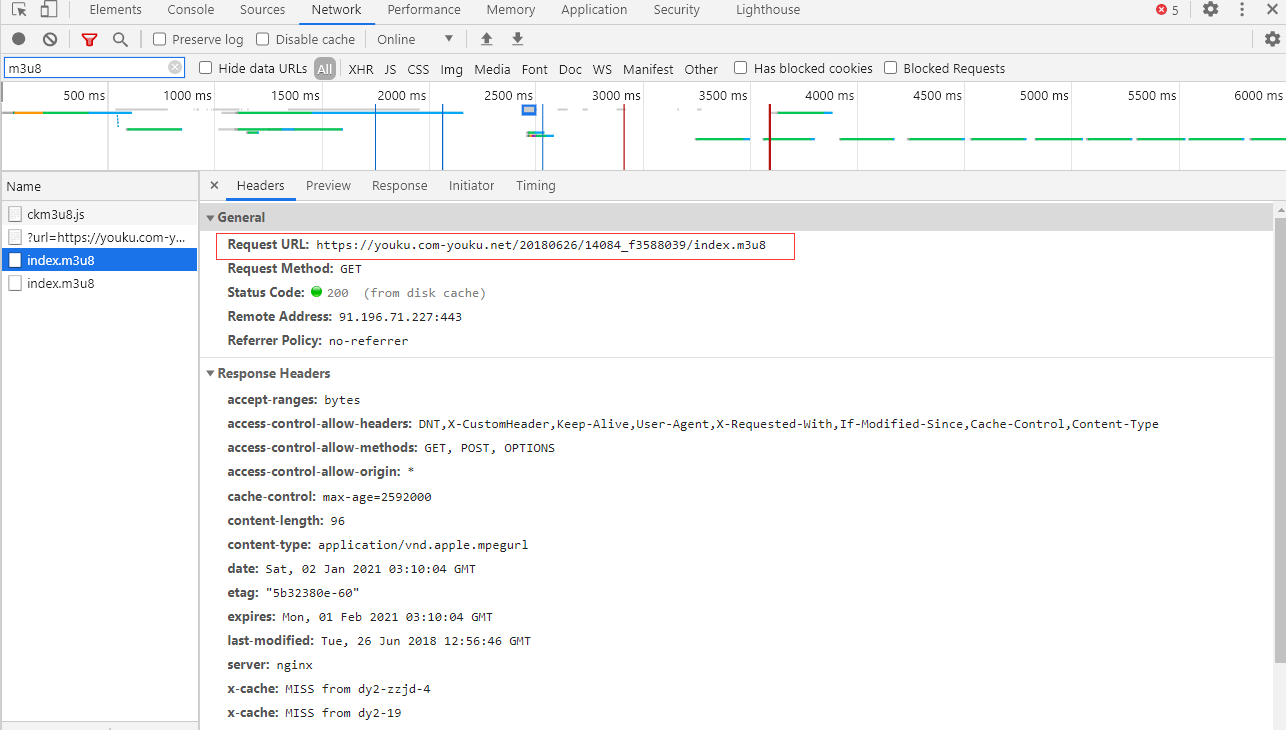
 第一个m3u8文件内容
第一个m3u8文件内容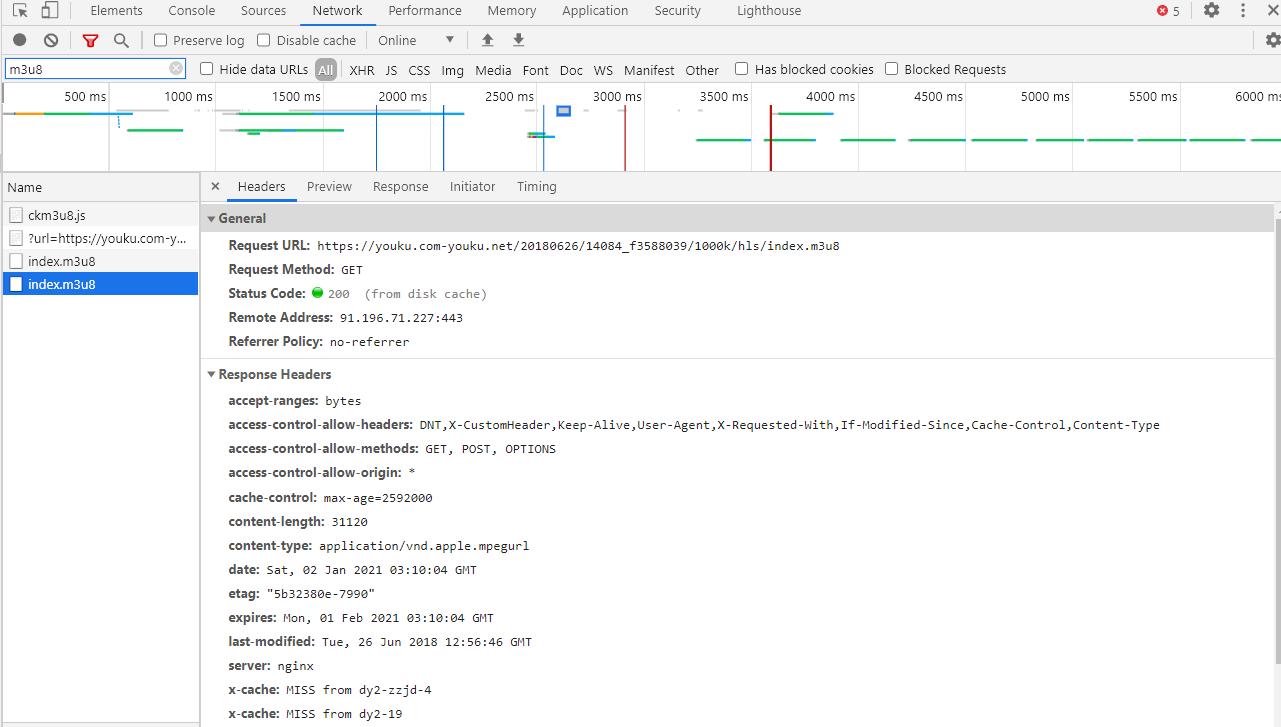
 第二个m3u8文件内容
第二个m3u8文件内容